Hive catalog
Hive catalog は、StarRocks が v2.4 以降でサポートする外部カタログの一種です。Hive catalog では以下のことができます:
- Hive に保存されているデータを、テーブルを手動で作成することなく直接クエリできます。
- INSERT INTO または非同期マテリアライズドビュー(v2.5 以降でサポート)を使用して、Hive に保存されているデータを処理し、StarRocks にデータをロードできます。
- StarRocks 上で操作を行い、Hive データベースやテーブルを作成または削除したり、StarRocks テーブルから Parquet 形式(v3.2 以降でサポート)および ORC または Textfile 形式(v3.3 以降でサポート)の Hive テーブルにデータをシンクできます。
Hive クラスターでの SQL ワークロードを成功させるためには、StarRocks クラスターが Hive クラスターのストレージシステムとメタストアにアクセスできる必要があります。StarRocks は以下のストレージシステムとメタストアをサポートしています:
-
分散ファイルシステム(HDFS)または AWS S3、Microsoft Azure Storage、Google GCS、その他の S3 互換ストレージシステム(例:MinIO)
-
メタストアとして Hive メタストアまたは AWS Glue
注記ストレージとして AWS S3 を選択した場合、メタストアとして HMS または AWS Glue を使用できます。他のストレージシステムを選択した場合、メタストアとしては HMS のみを使用できます。
使用上の注意
-
StarRocks は、Parquet、ORC、Textfile、Avro、RCFile、SequenceFile ファイル形式の Hive テーブルに対するクエリをサポートしています:
- Parquet ファイルは、以下の圧縮形式をサポートしています:SNAPPY、LZ4、ZSTD、GZIP、NO_COMPRESSION。v3.1.5 以降、Parquet ファイルは LZO 圧縮形式もサポートしています。
- ORC ファイルは、以下の圧縮形式をサポートしています:ZLIB、SNAPPY、LZO、LZ4、ZSTD、NO_COMPRESSION。
- Textfile ファイルは、v3.1.5 以降、LZO 圧縮形式をサポートしています。
-
StarRocks がサポートしていない Hive のデータ型は INTERVAL��、BINARY、UNION です。さらに、StarRocks は Textfile 形式の Hive テーブルに対して MAP および STRUCT データ型をサポートしていません。
-
StarRocks は、Parquet 形式(v3.2 以降でサポート)および ORC または Textfile 形式(v3.3 以降でサポート)の Hive テーブルへのデータのシンクをサポートしています:
- Parquet および ORC ファイルは、以下の圧縮形式をサポートしています:NO_COMPRESSION、SNAPPY、LZ4、ZSTD、GZIP。
- Textfile ファイルは、NO_COMPRESSION 圧縮形式をサポートしています。
テーブルプロパティ
compression_codecまたはシステム変数connector_sink_compression_codecを使用して、Hive テーブルへのデータシンクに使用する圧縮アルゴリズムを指定できます。Hive テーブルへの書き込み時、テーブルのプロパティに圧縮コーデックが含まれている場合、StarRocks は書き込みデータの圧縮にそのアルゴリズムを優先的に使用します。そうでない場合、システム変数
connector_sink_compression_codecで設定された圧縮アルゴリズムが使用されます。
統合準備
Hive catalog を作成する前に、StarRocks クラスターが Hive クラスターのストレージシステムとメタストアと統合できることを確認してください。
AWS IAM
Hive クラスターがストレージとして AWS S3 を使用している場合、またはメタストアとして AWS Glue を使用している場合、適切な認証方法を選択し、StarRocks クラスターが関連する AWS クラウドリソースにアクセスできるように必要な準備を行ってください。
以下の認証方法が推奨されます:
- インスタンスプロファイル
- 想定ロール
- IAM ユーザー
上記の三つの認証方法の中で、インスタンスプロファイルが最も広く使用されています。
詳細については、AWS IAM での認証準備を参照してください。
HDFS
ストレージとして HDFS を選択した場合、StarRocks クラスターを次のように構成します:
-
(オプション)HDFS クラスターおよび Hive メタストアにアクセスするために使用されるユーザー名を設定します。デフォルトでは、StarRocks は HDFS クラスターおよび Hive メタストアにアクセスするために FE および BE または CN プロセスのユーザー名を使用します。また、各 FE の fe/conf/hadoop_env.sh ファイルの先頭、および各 BE または CN の be/conf/hadoop_env.sh ファイルまたは cn/conf/hadoop_env.sh ファイルの先頭に
export HADOOP_USER_NAME="<user_name>"を追加してユーザー名を設定することもできます。これらのファイルでユーザー名を設定した後、各 FE および各 BE または CN を再起動して、パラメータ設定を有効にします。StarRocks クラスターごとに一つのユーザー名のみを設定できます。 -
Hive データをクエリする際、StarRocks クラスターの FEs および BEs または CNs は HDFS クライアントを使用して HDFS クラスターにアクセスします。ほとんどの場合、その目的を達成するために StarRocks クラスターを構成する必要はなく、StarRocks はデフォルトの構成を使用して HDFS クライアントを起動します。次の状況でのみ StarRocks クラスターを構成する必要があります:
- HDFS クラスターに高可用性 (HA) が有効になっている場合:HDFS クラスターの hdfs-site.xml ファイルを各 FE の $FE_HOME/conf パス、および各 BE または CN の $BE_HOME/conf パスに追加します。
- HDFS クラスターに View File System (ViewFs) が有効になっている場合:HDFS クラスターの core-site.xml ファイルを各 FE の $FE_HOME/conf パス、および各 BE または CN の $BE_HOME/conf パスに追加します。
クエリを送信した際に不明なホストを示すエラーが返された場合、HDFS クラスターのノードのホスト名と IP アドレスのマッピングを /etc/hosts パスに追加する必要があります。
Kerberos 認証
HDFS クラスターまたは Hive メタストアに Kerberos 認証が有効になっている場合、StarRocks クラスターを次のように構成します:
- 各 FE および各 BE または CN で
kinit -kt keytab_path principalコマンドを実行して、Key Distribution Center (KDC) から Ticket Granting Ticket (TGT) を取得します。このコマンドを実行するには、HDFS クラスターおよび Hive メタストアにアクセスする権限が必要です。このコマンドを使用して KDC にアクセスすることは時間に敏感です。したがって、このコマンドを定期的に実行するために cron を使用する必要があります。 - 各 FE の $FE_HOME/conf/fe.conf ファイル、および各 BE または CN の $BE_HOME/conf/be.conf ファイルに
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"を追加します。この例では、/etc/krb5.confは krb5.conf ファイルの保存パスです。必要に応じてパスを変更できます。
Hive catalog の作成
構文
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "hive",
GeneralParams,
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
パラメータ
catalog_name
Hive catalog の名前です。命名規則は以下の通りです:
- 名前には文字、数字(0-9)、アンダースコア(_)を含めることができます。文字で始まる必要があります。
- 名前は大文字と小文字を区別し、長さは 1023 文字を超えてはなり�ません。
comment
Hive catalog の説明です。このパラメータはオプションです。
type
データソースのタイプです。値を hive に設定します。
GeneralParams
一般的なパラメータのセットです。
GeneralParams で構成できるパラメータを以下の表に示します。
| Parameter | Required | Description |
|---|---|---|
| enable_recursive_listing | No | StarRocks がテーブルとそのパーティション、およびテーブルとそのパーティションの物理的な場所内のサブディレクトリからデータを読み取るかどうかを指定します。 有効な値:true および false。 デフォルト値:true。 値 true はサブディレクトリを再帰的にリストすることを指定し、値 false はサブディレクトリを無視することを指定します。 |
MetastoreParams
StarRocks がデータソースのメタストアと統合する方法に�関するパラメータのセットです。
Hive メタストア
データソースのメタストアとして Hive メタストアを選択した場合、MetastoreParams を次のように構成します:
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
Hive データをクエリする前に、Hive メタストアノードのホスト名と IP アドレスのマッピングを /etc/hosts パスに追加する必要があります。そうしないと、クエリを開始したときに StarRocks が Hive メタストアにアクセスできない可能性があります。
MetastoreParams で構成する必要があるパラメータを以下の表に示します。
| Parameter | Required | Description |
|---|---|---|
| hive.metastore.type | Yes | Hive クラスターで使用するメタストアのタイプです。値を hive に設定します。 |
| hive.metastore.uris | Yes | Hive メタストアの URI です。形式:thrift://<metastore_IP_address>:<metastore_port>。Hive メタストアに高可用性 (HA) が有効になっている場合、複数のメタストア URI を指定し、カンマ( ,)で区切ることができます。例:"thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>"。 |
AWS Glue
データソースの�メタストアとして AWS Glue を選択した場合、これはストレージとして AWS S3 を選択した場合にのみサポートされます。以下のいずれかの操作を行います:
-
インスタンスプロファイルベースの認証方法を選択する場合、
MetastoreParamsを次のように構成します:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
想定ロールベースの認証方法を選択する場合、
MetastoreParamsを次のように構成します:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
IAM ユーザーベースの認証方法を選択する場合、
MetastoreParamsを次のように構成します:"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
MetastoreParams で構成する必要があるパラメータを以下の表に示します。
| Parameter | Required | Description |
|---|---|---|
| hive.metastore.type | Yes | Hive クラスターで使用するメタストアのタイプです。値を glue に設定します。 |
| aws.glue.use_instance_profile | Yes | インスタンスプロファイルベースの認証方法と想定ロールベースの認証を有効にするかどうかを指定します。 有効な値:true および false。 デフォルト値:false。 |
| aws.glue.iam_role_arn | No | AWS Glue Data Catalog に対する権限を持つ IAM ロールの ARN です。AWS Glue にアクセスするために想定ロールベースの認証方法を使用する場合、このパラメー��タを指定する必要があります。 |
| aws.glue.region | Yes | AWS Glue Data Catalog が存在するリージョンです。例:us-west-1。 |
| aws.glue.access_key | No | AWS IAM ユーザーのアクセスキーです。IAM ユーザーベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。 |
| aws.glue.secret_key | No | AWS IAM ユーザーのシークレットキーです。IAM ユーザーベースの認証方法を使用して AWS Glue にアクセスする場合、このパラメータを指定する必要があります。 |
| hive.metastore.glue.catalogid | No | 使用する AWS Glue Data Catalog の ID。指定しない場合、現在の AWS アカウントのカタログが使用されます。別の AWS アカウントの Glue Data Catalog にアクセスする(クロスアカウントアクセス)必要がある場合は、このパラメータを指定する必要があります。 |
AWS Glue にアクセスするための認証方法の選択方法や AWS IAM コンソールでのアクセス制御ポリシーの設定方法については、AWS Glue にアクセスするための認証パラメータを参照してください。
StorageCredentialParams
StarRocks がストレージシステムと統合する方法に関するパラメータのセットです。このパラメータセットはオプションです。
ストレージとして HDFS を使用する場合、StorageCredentialParams を構成する必要はありません。
ストレージとして AWS S3、その他の S3 互換ストレージシステム、Microsoft Azure Storage、または Google GCS を使用する場合、StorageCredentialParams を構成する必要があります。
AWS S3
Hive クラスターのストレージとして AWS S3 を選択した場合、以下のいずれかの操作を行います:
-
インスタンスプロファイルベースの認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
想定ロールベースの認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
IAM ユーザーベースの認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
StorageCredentialParams で構成する必要があるパラメータを以下の表に示します。
| Parameter | Required | Description |
|---|---|---|
| aws.s3.use_instance_profile | Yes | インスタンスプロファイルベースの認証方法と想定ロールベースの認証方法を有効にするかどうかを指定します。 有効な値:true および false。 デフォルト値:false。 |
| aws.s3.iam_role_arn | No | AWS S3 バケットに対する権限を持つ IAM ロールの ARN です。AWS S3 にアクセスするために想定ロールベースの認証方法を使用する場合、このパラメータを指定する必要があります。 |
| aws.s3.region | Yes | AWS S3 バケットが存在するリージョンです。例:us-west-1。 |
| aws.s3.access_key | No | IAM ユーザーのアクセスキーです。IAM ユーザーベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメータを指定する必要があります。 |
| aws.s3.secret_key | No | IAM ユーザーのシークレットキーです。IAM ユーザーベースの認証方法を使用して AWS S3 にアクセスする場合、このパラメータを指定する必要があります。 |
AWS S3 にアクセスするための認証方法の選択方法や AWS IAM コンソールでのアクセス制御ポリシーの設定方法については、AWS S3 にアクセスするための認証パラメータを参照してください。
S3 互換ストレージシステム
Hive catalog は v2.5 以降、S3 互換ストレージシステムをサポートしています。
S3 互換ストレージシステム(例:MinIO)を選択した場合、StorageCredentialParams を次のように構成して、統合を成功させます:
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
StorageCredentialParams で構成する必要があるパラメータを以下の表に示します。
| Parameter | Required | Description |
|---|---|---|
| aws.s3.enable_ssl | Yes | SSL 接続を有効にするかどうかを指定します。 有効な値: true および false。 デフォルト値:true。 |
| aws.s3.enable_path_style_access | Yes | パススタイルアクセスを有効にするかどうかを指定します。 有効な値: true および false。 デフォルト値:false。MinIO の場合、値を true に設定する必要があります。パススタイル URL は次の形式を使用します: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>。 例:US West (Oregon) リージョンに DOC-EXAMPLE-BUCKET1 というバケットを作成し、そのバケット内の alice.jpg オブジェクトにアクセスする場合、次のパススタイル URL を使用できます:https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg。 |
| aws.s3.endpoint | Yes | AWS S3 の代わりに S3 互換ストレージシステムに接続するために使用されるエンドポイントです。 |
| aws.s3.access_key | Yes | IAM ユーザーのアクセスキーです。 |
| aws.s3.secret_key | Yes | IAM ユーザーのシークレットキーです。 |
Microsoft Azure Storage
Hive catalog は v3.0 以降、Microsoft Azure Storage をサポートしています。
Azure Blob Storage
Hive クラスターのストレージとして Blob Storage を選択した場合、以下のいずれかの操作を行います:
-
共有キー認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.blob.storage_account Yes Blob Storage アカウントのユーザー名です。 azure.blob.shared_key Yes Blob Storage アカウントの共有キーです。 -
SAS トークン認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.blob.storage_account Yes Blob Storage アカウントのユーザー名です。 azure.blob.container Yes データを保存する Blob コンテナの名前です。 azure.blob.sas_token Yes Blob Storage アカウントにアクセスするために使用される SAS トークンです。
Azure Data Lake Storage Gen2
Hive クラスターのストレージとして Data Lake Storage Gen2 を選択した場合、以下のいずれかの操作を行います:
-
マネージド ID 認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.adls2.oauth2_use_managed_identity Yes マネージド ID 認証方法を有効にするかどうかを指定します。値を trueに設定します。azure.adls2.oauth2_tenant_id Yes アクセスしたいデータのテナント ID です。 azure.adls2.oauth2_client_id Yes マネージド ID のクライアント(アプリケーション)ID です。 -
共有キー認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.adls2.storage_account Yes Data Lake Storage Gen2 ストレージアカウントのユーザー名です。 azure.adls2.shared_key Yes Data Lake Storage Gen2 ストレージアカウントの共有キーです。 -
サービスプリンシパル認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.adls2.oauth2_client_id Yes サービスプリンシパルのクライアント(アプリケーション)ID です。 azure.adls2.oauth2_client_secret Yes 作成された新しいクライアント(アプリケーション)シークレットの値です。 azure.adls2.oauth2_client_endpoint Yes サービスプリンシパルまたはアプリケーションの OAuth 2.0 トークンエンドポイント(v1)です。
Azure Data Lake Storage Gen1
Hive クラスターのストレージとして Data Lake Storage Gen1 を選択した場合、以下のいずれかの操作を行います:
-
マネージドサービス ID 認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.adls1.use_managed_service_identity" = "true"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.adls1.use_managed_service_identity Yes マネージドサービス ID 認証方法を有効にするかどうかを指定します。値を trueに設定します。 -
サービスプリンシパル認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Required Description azure.adls1.oauth2_client_id Yes サービスプリンシパルのクライアント(アプリケーション)ID です。 azure.adls1.oauth2_credential Yes 作成された新しいクライアン��ト(アプリケーション)シークレットの値です。 azure.adls1.oauth2_endpoint Yes サービスプリンシパルまたはアプリケーションの OAuth 2.0 トークンエンドポイント(v1)です。
Google GCS
Hive catalog は v3.0 以降、Google GCS をサポートしています。
Hive クラスターのストレージとして Google GCS を選択した場合、以下のいずれかの操作を行います:
-
VM ベースの認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"gcp.gcs.use_compute_engine_service_account" = "true"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Default value Value example Description gcp.gcs.use_compute_engine_service_account false true コンピュートエンジンにバインドされたサービスアカウントを直接使用するかどうかを指定します。 -
サービスアカウントベースの認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Default value Value example Description gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" サービスアカウントの作成時に生成された JSON ファイルのメールアドレスです。 gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" サービスアカウントの作成時に生成された JSON ファイルのプライベートキー ID です。 gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" サービスアカウントの作成時に生成された JSON ファイルのプライベートキーです。 -
インパーソネーションベースの認証方法を選択する場合、
StorageCredentialParamsを次のように構成します:-
VM インスタンスにサービスアカウントをインパーソネートさせる場合:
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Default value Value example Description gcp.gcs.use_compute_engine_service_account false true コンピュートエンジンにバインドされたサービスアカウントを直接使用するかどうかを指定します。 gcp.gcs.impersonation_service_account "" "hello" インパーソネートしたいサービスアカウントです。 -
サービスアカウント(仮にメタサービスアカウントと呼ぶ)が別のサービスアカウント(仮にデータサービスアカウントと呼ぶ)をインパーソネートする場合:
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"StorageCredentialParamsで構成する必要があるパラメータを以下の表に示します。Parameter Default value Value example Description gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" メタサービスアカウントの作成時に生成された JSON ファイルのメールアドレスです。 gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" メタサービスアカウントの作成時に生成された JSON ファイルのプライベートキー ID です。 gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" メタサービスアカウントの作成時に生成された JSON ファイルのプライベートキーです。 gcp.gcs.impersonation_service_account "" "hello" インパーソネートしたいデータサービスアカウントです。
-
MetadataUpdateParams
StarRocks が Hive のキャッシュされたメタデータを更新する方法に関するパラメータのセットです。このパラメータセットはオプションです。
StarRocks はデフォルトで 自動非同期更新ポリシー を実装しています。
ほとんどの場合、MetadataUpdateParams を無視し、その中のポリシーパラメータを調整する必要はありません。これらのパラメータのデフォルト値は、すぐに使えるパフォーマンスを提供します。
ただし、Hive のデータ更新頻度が高い場合、これらのパラメータを調整して自動非同期更新のパフォーマンスをさらに最適化できます。
ほとんどの場合、Hive データが 1 時間以下の粒度で更新される場合、データ更新頻度は高いと見なされます。
| Parameter | Required | Description |
|---|---|---|
| enable_metastore_cache | No | StarRocks が Hive テーブルのメタデータをキャッシュするかどうかを指定します。 有効な値:true および false。 デフォルト値:true。 値 true はキャッシュを有効にし、値 false はキャッシュを無効にします。 |
| enable_remote_file_cache | No | StarRocks が Hive テーブルまたはパーティションの基礎データファイルのメタデータをキャッシュするかどうかを指定します。 有効な値:true および false。 デフォルト値:true。 値 true はキャッシュを有効にし、値 false はキャッシュを無効にします。 |
| metastore_cache_refresh_interval_sec | No | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションのメタデータを非同期に更新する時間間隔です。 単位:秒。 デフォルト値:60(1 分)。 v3.3.0 以降、このプロパティのデフォルト値は 7200 から 60 に変更されました。 |
| remote_file_cache_refresh_interval_sec | No | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションの基礎データファイルのメタデータを非同期に更新する時間間隔です。 単位:秒。 デフォルト値:60。 |
| metastore_cache_ttl_sec | No | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションのメタデータを自動的に破棄する時間間隔です。 単位:秒。 デフォルト値:86400(24 時間)。 |
| remote_file_cache_ttl_sec | No | StarRocks が自身にキャッシュされた Hive テーブルまたはパーティションの基礎データファイルのメタデータを自動的に破棄する時間間隔です。 単位:秒。 デフォルト値:129600(36 時間)。 |
| enable_cache_list_names | No | StarRocks が Hive パーティション名をキャッシュするかどうかを指定します。 有効な値:true および false。 デフォルト値:true。 値 true はキャッシュを有効にし、値 false はキャッシュを無効にします。 |
| remote_file_cache_memory_ratio | No | Remote File Cache の最大メモリ使用率。デフォルト値: 0.1(10%)。v3.5.6 以降でサポート。 |
例
以下の例では、使用するメタストアのタイプに応じて、hive_catalog_hms または hive_catalog_glue という名前の Hive catalog を作成し、Hive クラスターからデータをクエリします。
HDFS
ストレージとして HDFS を使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
AWS S3
インスタンスプロファイルベースの認証
-
Hive クラスターで Hive メタストアを使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Hive クラスターで AWS Glue を使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
想定ロールベースの認証
-
Hive クラスターで Hive メタストアを使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Hive クラスターで AWS Glue を使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
IAM ユーザーベースの認証
-
Hive クラスターで Hive メタストアを使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
Amazon EMR Hive クラスターで AWS Glue を使用する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_glue
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
S3 互換ストレージシステム
MinIO を例にとります。以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
共有キー認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
SAS トークン認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
マネージドサービス ID 認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
サービスプリンシパル認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
マネージド ID 認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
共有キー認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
サービスプリンシパル認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
VM ベースの認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
サービスアカウントベースの認証方法を選択する場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
インパーソネーションベースの認証方法を選択する場合:
-
VM インスタンスにサービスアカウントをインパーソネートさせる場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
サービスアカウントが別のサービスアカウントをインパーソネートする場合、以下のようなコマンドを実行します:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
Hive catalog の表示
現在の StarRocks クラスター内のすべてのカタログをクエリするには、SHOW CATALOGS を使用できます:
SHOW CATALOGS;
外部カタログの作成ステートメントをクエリするには、SHOW CREATE CATALOG を使用できます。以下の例では、hive_catalog_glue という名前の Hive catalog の作成ステートメントをクエリします:
SHOW CREATE CATALOG hive_catalog_glue;
Hive catalog とその中のデータベースに切り替える
Hive catalog とその中のデータベースに切り替えるには、次の方法のいずれかを使用できます:
-
現在のセッションで Hive catalog を指定するには SET CATALOG を使用し、その後 USE を使用してアクティブなデータベースを指定します:
-- 現在のセッションで指定されたカタログに切り替えます:
SET CATALOG <catalog_name>
-- 現在のセッションでアクティブなデータベースを指定します:
USE <db_name> -
USE を直接使用して、Hive catalog とその中のデータベースに切り替えます:
USE <catalog_name>.<db_name>
Hive catalog の削除
外部カタログを削除するには、DROP CATALOG を使用できます。
以下の例では、hive_catalog_glue という名前の Hive catalog を削除します:
DROP Catalog hive_catalog_glue;
Hive テーブルのスキーマを表示する
Hive テーブルのスキーマを表示するには、次の構文のいずれかを使用できます:
-
スキーマを表示
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
CREATE ステートメントからスキーマと場所を表示
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
Hive テーブルのクエリ
-
SHOW DATABASES を使用して、Hive クラスター内のデータベースを表示します:
SHOW DATABASES FROM <catalog_name> -
SELECT を使用して、指定されたデータベース内の目的のテーブルをクエリします:
SELECT count(*) FROM <table_name> LIMIT 10
Hive からのデータのロード
olap_tbl という名前の OLAP テーブルがあると仮定し、以下のようにデータを変換してロードできます:
INSERT INTO default_catalog.olap_db.olap_tbl SELECT * FROM hive_table
Hive テーブルおよびビューへの権限の付与
GRANT ステートメントを使用して、特定のロールに Hive catalog 内のすべてのテーブルおよびビューに対する権限を付与できます。コマンド構文は次のとおりです:
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE <role_name>
例として、以下のコマンドを使用して hive_role_table という名前のロールを作成し、Hive catalog hive_catalog に切り替え、その後 hive_role_table ロールに Hive catalog hive_catalog 内のすべてのテーブルおよびビューをクエリする権限を付与します:
-- hive_role_table という名前のロールを作成します。
CREATE ROLE hive_role_table;
-- Hive catalog hive_catalog に切り替えます。
SET CATALOG hive_catalog;
-- hive_role_table ロールに Hive catalog hive_catalog 内のすべてのテーブルおよびビューをクエリする権限を付与します。
GRANT SELECT ON ALL TABLES IN ALL DATABASES TO ROLE hive_role_table;
Hive データベースの作成
StarRocks の内部カタログと同様に、Hive catalog に対する CREATE DATABASE 権限を持っている場合、CREATE DATABASE ステートメントを使用してその Hive catalog にデータベースを作成できます。この機能は v3.2 以降でサポートされています。
Hive catalog に切り替える その後、次のステートメントを使用してそのカタログに Hive データベースを作成します:
CREATE DATABASE <database_name>
[PROPERTIES ("location" = "<prefix>://<path_to_database>/<database_name.db>")]
location パラメータは、データベースを作成したいファイルパスを指定します。これは HDFS またはクラウドストレージにすることができます。
- Hive クラスターのメタストアとして Hive メタストアを使用する場合、
locationパラメータは<warehouse_location>/<database_name.db>にデフォルト設定されます。データベース作成時にそのパラ�メータを指定しない場合、これは Hive メタストアによってサポートされます。 - Hive クラスターのメタストアとして AWS Glue を使用する場合、
locationパラメータにはデフォルト値がなく、したがってデータベース作成時にそのパラメータを指定する必要があります。
prefix は使用するストレージシステムに基づいて異なります:
| Storage system | Prefix value |
|---|---|
| HDFS | hdfs |
| Google GCS | gs |
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen1 | adl |
| Azure Data Lake Storage Gen2 |
|
| AWS S3 またはその他の S3 互換ストレージ(例:MinIO) | s3 |
Hive データベースの削除
StarRocks の内部データベースと同様に��、Hive データベースに対する DROP 権限を持っている場合、DROP DATABASE ステートメントを使用してその Hive データベースを削除できます。この機能は v3.2 以降でサポートされています。空のデータベースのみを削除できます。
Hive データベースを削除すると、そのデータベースのファイルパスは HDFS クラスターまたはクラウドストレージ上に残りますが、データベースと共に削除されません。
Hive catalog に切り替える その後、次のステートメントを使用してそのカタログに Hive データベースを削除します:
DROP DATABASE <database_name>
Hive テーブルの作成
StarRocks の内部データベースと同様に、Hive データベースに対する CREATE TABLE 権限を持っている場合、CREATE TABLE、CREATE TABLE AS SELECT、または CREATE TABLE LIKE ステートメントを使用してその Hive データベースに管理テーブルを作成できます。
この機能は v3.2 以降でサポートされており、そのバージョンでは StarRocks は Parquet 形式の Hive テーブルの作成のみをサポートしています。v3.3 以降、StarRocks は ORC および Textfile 形式の Hive テーブルの作成もサポートしています。
Hive catalog とその中のデータベースに切り替える その後、次の構文を使用してそのデータベースに Hive 管理テーブルを作成します。
構文
CREATE TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...
partition_column_definition1,partition_column_definition2...])
[partition_desc]
[PROPERTIES ("key" = "value", ...)]
[AS SELECT query]
[LIKE [database.]<source_table_name>]
パラメータ
column_definition
column_definition の構文は次のとおりです:
col_name col_type [COMMENT 'comment']
以下の表にパラメータを示します。
| Parameter | Description |
|---|---|
| col_name | カラムの名前です。 |
| col_type | カラムのデータ型です。サポートされているデータ型は次のとおりです:TINYINT、SMALLINT、INT、BIGINT、FLOAT、DOUBLE、DECIMAL、DATE、DATETIME、CHAR、VARCHAR[(length)]、ARRAY、MAP、STRUCT。LARGEINT、HLL、BITMAP データ型はサポートされていません。 |
NOTICE
すべての非パーティションカラムは
NULLをデフォルト値として使用する必要があります。つまり、テーブル作成ステートメントで各非パーティションカラムに対してDEFAULT "NULL"を指定する必要があります。さらに、パーティションカラムは非パーティションカラムの後に定義され、NULLをデフォルト値として使用することはできません。
partition_desc
partition_desc の構文は次のとおりです:
PARTITION BY (par_col1[, par_col2...])
現在、StarRocks はアイデンティティ変換のみをサポートしており、これは StarRocks が各ユニークなパーティション値に対してパーティションを作成することを意味します。
NOTICE
パーティションカラムは非パーティションカラムの後に定義される必要があります。パーティションカラムは FLOAT、DOUBLE、DECIMAL、DATETIME を除くすべてのデータ型をサポートし、
NULLをデフォルト値として使用することはできません。さらに、partition_descで宣言されたパーティションカラムの順序は、column_definitionで定義されたカラムの順序と一致している必要があります。
PROPERTIES
properties で "key" = "value" 形式でテーブル属性を指定できます。
以下の表にいくつかの主要なプロパティを示します。
| Property | Description |
|---|---|
| location | 管理テーブルを作成したいファイ�ルパスです。HMS をメタストアとして使用する場合、location パラメータを指定する必要はありません。StarRocks は現在の Hive catalog のデフォルトファイルパスにテーブルを作成します。AWS Glue をメタデータサービスとして使用する場合:
|
| file_format | 管理テーブルのファイル形式です。サポートされているファイル形式は Parquet、ORC、Textfile です。ORC および Textfile 形式は v3.3 以降でサポートされています。 有効な値:parquet、orc、textfile。 デフォルト値:parquet。 |
| compression_codec | 管理テーブルに使用される圧縮アルゴリズムです。 |
例
以下の DDL はデフォルトのファイル形式 Parquet を例にとります。
-
unpartition_tblという名前の非パーティションテーブルを作成します。このテーブルはidとscoreの二つのカラムで構成されています。以下に示します:CREATE TABLE unpartition_tbl
(
id int,
score double
); -
partition_tbl_1という名前のパーティションテーブルを作成します。このテーブルはaction、id、dtの三つのカラムで構成されており、そのうちidとdtがパーティションカラムとして定義されています。以下に示します:CREATE TABLE partition_tbl_1
(
action varchar(20),
id int,
dt date
)
PARTITION BY (id,dt); -
既存の
partition_tbl_1テーブルをクエリし、そのクエリ結果に基づいてpartition_tbl_2という名前のパーティションテーブルを作成します。partition_tbl_2では、idとdtがパーティションカラムとして定義されています。以下に示します:CREATE TABLE partition_tbl_2
PARTITION BY (k1, k2)
AS SELECT * from partition_tbl_1;
Hive テーブルへのデータのシンク
StarRocks の内部テーブルと同様に、Hive テーブル(管理テーブルまたは外部テーブル)に対する INSERT 権限を持っている場合、INSERT ステートメントを使用して StarRocks テーブルのデータをその Hive テーブルにシンクできます。
この機能は v3.2 以降でサポートされており、そのバージョンではデータは Parquet 形式の Hive テーブルにのみシンクできます。v3.3 以降、StarRocks は ORC および Textfile 形式の Hive テーブルへのデータのシンクもサポートしています。
外部テーブルへのデータのシンクはデフォルトで無効になっています。外部テーブルにデータをシンクするには、システム変数 ENABLE_WRITE_HIVE_EXTERNAL_TABLE を true に設定する必要があります。
- GRANT および REVOKE を使用して権限を付与および取り消すことができます。
- テーブルプロパティ
compression_codecまたはシステム変数 [connector_sink_compression_codec](../../sql-reference/System_variable.md# connector_sink_compression_codec) を使用して、Hive テーブルへのデータシンクに適用する圧縮アルゴリズムを指定できます。StarRocks はテーブルプロパティで指定された圧縮コーデックを優先的に使用します。
Hive catalog とその中のデータベースに切り替える その後、次の構文を使用してそのデータベース内の Parquet 形式の Hive テーブルに StarRocks テーブルのデータをシンクします。
構文
INSERT {INTO | OVERWRITE} <table_name>
[ (column_name [, ...]) ]
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
-- 指定されたパーティションにデータをシンクしたい場合、次の構文を使用します:
INSERT {INTO | OVERWRITE} <table_name>
PARTITION (par_col1=<value> [, par_col2=<value>...])
{ VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
NOTICE
パーティションカラムは
NULL値を許可しません。したがって、Hive テーブルのパーティションカラムに空の値がロードされないようにする必要があります。
パラメータ
| Parameter | Description |
|---|---|
| INTO | StarRocks テーブルのデータを Hive テーブルに追加します。 |
| OVERWRITE | Hive テーブルの既存のデータを StarRocks テーブルのデータで上書きします。 |
| column_name | データをロードしたい宛先カラムの名前です。1 つ以上のカラムを指定できます。複数のカラムを指定する場合、カンマ(,)で区切ります。Hive テーブルに実際に存在するカラムのみを指定できます。また、指定した宛先カラムには Hive テーブルのパーティションカラムを含める必要があります。指定した宛先カラムは、StarRocks テーブルのカラムと順番に 1 対 1 でマッピングされます。宛先カラムが指定されていない場合、データは Hive テーブルのすべてのカラムにロードされます。StarRocks テーブルの非パーティションカラムが Hive テーブルのカラムにマッピングできない場合、StarRocks は Hive テーブルのカラムにデフォルト値 NULL を書き込みます。INSERT ステートメントに含まれるクエリステートメントの返されるカラムタイプが宛先カラムのデータ型と異なる場合、StarRocks は不一致のカラムに対して暗黙的な変換を行います。変換が失敗した場合、構文解析エラーが返されます。 |
| expression | 宛先カラムに値を割り当てる式です。 |
| DEFAULT | 宛先カラムにデフォルト値を割り当てます。 |
| query | Hive テーブルにロードされる結果を持つクエリステートメントです。StarRocks がサポートする任意の SQL ステートメントを使用できます。 |
| PARTITION | データをロードしたいパーティションです。このプロパティには Hive テーブルのすべてのパーティションカラムを指定する必要があります。このプロパティで指定するパーティションカラムは、テーブル作成ステートメントで定義したパーティションカラムの順序と異なる順序で指定できます。このプロパティを指定する場合、column_name プロパティを指定することはできません。 |
例
以下の DML はデフォルトのファイル形式 Parquet を例にとります。
-
partition_tbl_1テーブルに 3 行のデータを挿入します:INSERT INTO partition_tbl_1
VALUES
("buy", 1, "2023-09-01"),
("sell", 2, "2023-09-02"),
("buy", 3, "2023-09-03"); -
簡単な計算を含む SELECT クエリの結果を
partition_tbl_1テーブルに挿入します:INSERT INTO partition_tbl_1 (id, action, dt) SELECT 1+1, 'buy', '2023-09-03'; -
partition_tbl_1テーブルからデータを読み取る SELECT クエリの結果を同じテーブルに挿入します:INSERT INTO partition_tbl_1 SELECT 'buy', 1, date_add(dt, INTERVAL 2 DAY)
FROM partition_tbl_1
WHERE id=1; -
partition_tbl_2テーブルのdt='2023-09-01'およびid=1の条件を満たすパーティションに SELECT クエリの結果を挿入します:INSERT INTO partition_tbl_2 SELECT 'order', 1, '2023-09-01';または
INSERT INTO partition_tbl_2 partition(dt='2023-09-01',id=1) SELECT 'order'; -
partition_tbl_1テーブルのdt='2023-09-01'およびid=1の条件を満たすパーティションのすべてのactionカラム値をcloseで上書きします:INSERT OVERWRITE partition_tbl_1 SELECT 'close', 1, '2023-09-01';または
INSERT OVERWRITE partition_tbl_1 partition(dt='2023-09-01',id=1) SELECT 'close';
Hive テーブルの Truncate
TRUNCATE TABLE ステートメントを使用して、Hive マネージドテーブルからすべてのデータを迅速に削除できます。この操作は以下をサポートしています:
- 非パーティションテーブルのすべてのデータを削除
- パーティションテーブルのすべてのパーティションを削除
- パーティションテーブルの特定のパーティションを削除
構文
TRUNCATE TABLE <table_name>
TRUNCATE TABLE <table_name> PARTITION (partition_name = partition_value [, ...])
パラメータ
table_name: データを削除する Hive テーブルの名前。データベース内のテーブルを削除する前に、Hive カタログとデータベースに切り替える必要があります。partition_name = partition_value: どのパーティションを削除するかを識別するための、パーティション列の名前と値。
使用例
Hive カタログとデータベースに切り替えた後、データベース内の Hive テーブルを以下のステートメントで truncate できます。
-
非パーティションテーブルを truncate:
TRUNCATE TABLE my_table; -
パーティションテーブルのすべてのパーティションを truncate:
TRUNCATE TABLE my_partitioned_table; -
単一パーティションテーブルの特定パーティションを truncate:
TRUNCATE TABLE my_partitioned_table PARTITION (dt='2023-09-01'); -
複数パーティションテーブルの特定パーティションを truncate:
TRUNCATE TABLE my_partitioned_table PARTITION (dt='2023-09-01', id=1);
TRUNCATE TABLE my_multi_part_table PARTITION (k2='2020-01-02', k3='b');
Hive テーブルの削除
StarRocks の内部テーブルと同様に、Hive テーブルに対する DROP 権限を持っている場合、DROP TABLE ステートメントを使用してその Hive テーブルを削除できます。この機能は v3.1 以降でサポートされています。現在、StarRocks は Hive の管理テーブルのみを削除することをサポートしています。
Hive テーブルを削除する際、DROP TABLE ステートメントに FORCE キーワードを指定する必要があります。操作が完了すると、テーブルのファイルパスは保持されますが、HDFS クラスターまたはクラウドストレージ上のテーブルのデータはすべてテーブルと共に削除されます。この操作を行う際は注意が必要です。
Hive catalog とその中のデータベースに切り替える その後、次のステートメントを使用してそのデータベース内の Hive テーブルを削除します。
DROP TABLE <table_name> FORCE
メタデータキャッシュの手動または自動更新
手動更新
デフォルトで、StarRocks は Hive のメタデータをキャッシュし、より良いパフォーマンスを提供するために非同期モードでメタデータを自動的に更新します。さらに、Hive テーブルでいくつかのスキーマ変更やテーブル更新が行われた後、REFRESH EXTERNAL TABLE を使用してそのメタデータを手動で更新することもできます。これにより、StarRocks が最新のメタデータをできるだけ早く取得し、適切な実行プランを生成できるようになります:
REFRESH EXTERNAL TABLE <table_name> [PARTITION ('partition_name', ...)]
次の状況でメタデータを手動で更新する必要があります:
-
既存のパーティション内のデータファイルが変更された場合、例:
INSERT OVERWRITE ... PARTITION ...コマンドを実行した場合。 -
Hive テーブルでスキーマ変更が行われた場合。
-
DROP ステートメントを使用して既存の Hive テーブルが削除され、削除された Hive テーブルと同じ名前の新しい Hive テーブルが作成された場合。
-
Hive catalog の作成時に
PROPERTIESで"enable_cache_list_names" = "true"を指定しており、Hive クラスターで新しく作成したパーティションをクエリしたい場合。注記v2.5.5 以降、StarRocks は定期的な Hive メタデータキャッシュの更新機能を提供しています。詳細については、以下の「メタデータキャッシュを定期的に更新する」セクションを参照してください。この機能を有効にすると、StarRocks はデフォルトで 10 分ごとに Hive メタデータキャッシュを更新します。したがって、ほとんどの場合、手動更新は必要ありません。新しいパーティションを Hive クラスターで作成した直後にクエリしたい場合にのみ、手動更新が必要です。
REFRESH EXTERNAL TABLE は、FEs にキャッシュされたテーブルとパーティションのみを更新します。
メタデータキャッシュを定期的に更新する
v2.5.5 以降、StarRocks は頻繁��にアクセスされる Hive catalog のキャッシュされたメタデータを定期的に更新してデータの変更を認識できます。次の FE パラメータ を通じて Hive メタデータキャッシュの更新を構成できます:
| Configuration item | Default | Description |
|---|---|---|
| enable_background_refresh_connector_metadata | true in v3.0false in v2.5 | 定期的な Hive メタデータキャッシュの更新を有効にするかどうか。 有効にすると、StarRocks は Hive クラスターのメタストア(Hive Metastore または AWS Glue)をポーリングし、頻繁にアクセスされる Hive catalog のキャッシュされたメタデータを更新してデータの変更を認識します。 true は Hive メタデータキャッシュの更新を有効にし、false は無効にします。この項目は FE 動的パラメータ です。ADMIN SET FRONTEND CONFIG コマンドを使用して変更できます。 |
| background_refresh_metadata_interval_millis | 600000 (10 minutes) | 二つの連続した Hive メタデータキャッシュの更新の間隔です。単位:ミリ秒。この項目は FE 動的パラメータ です。ADMIN SET FRONTEND CONFIG コマンドを使用して変更できます。 |
| background_refresh_metadata_time_secs_since_last_access_secs | 86400 (24 hours) | Hive メタデータキャッシュ更新タスクの有効期限です。アクセスされた Hive catalog に対して、指定された時間を超えてアクセスされていない場合、StarRocks はそのキャッシュされたメタデータの更新を停止します。アクセスされていない Hive catalog に対して、StarRocks はそのキャッシュされたメタデータを更新しません。単位:秒。この項目は FE 動的パラメータ です。ADMIN SET FRONTEND CONFIG コマンドを使用して変更できます。 |
定期的な Hive メタデータキャッシュの更新機能とメタデータ自動非同期更新ポリシーを組み合わせて使用することで、データアクセスが大幅に高速化され、外部データソースからの読み取り負荷が軽減され、クエリパフォーマンスが向上します。
付録:メタデータ自動非同期更新の理解
自動非同期更新は、StarRocks が Hive catalog のメタデータを更新するために使用するデフォルトのポリシーです。
デフォルトでは(つまり、enable_metastore_cache および enable_remote_file_cache パラメータが両方とも true に設定されている場合)、クエリが Hive テーブルのパーティションに�ヒットすると、StarRocks はそのパーティションのメタデータとそのパーティションの基礎データファイルのメタデータを自動的にキャッシュします。キャッシュされたメタデータは遅延更新ポリシーを使用して更新されます。
例えば、table2 という名前の Hive テーブルがあり、4 つのパーティション:p1、p2、p3、p4 があります。クエリが p1 にヒットし、StarRocks は p1 のメタデータと p1 の基礎データファイルのメタデータをキャッシュします。キャッシュされたメタデータを更新および破棄するデフォルトの時間間隔は次のとおりです:
p1のキャッシュされたメタデータを非同期に更新する時間間隔(metastore_cache_refresh_interval_secパラメータで指定)は 60 秒です。p1の基礎データファイルのキャッシュされたメタデータを非同期に更新する時間間隔(remote_file_cache_refresh_interval_secパラメータで指定)は 60 秒です。p1のキャッシュされたメタデータを自動的に破棄する時間間隔(metastore_cache_ttl_secパラメータで指定)は 24 時間です。p1の基礎データファイルのキャッシュされたメタデータを自動的に破棄する時間間隔(remote_file_cache_ttl_secパラメータで指定)は 36 時間です。
以下の図は、理解を容易にするための時間間隔をタイムライン上に示しています。
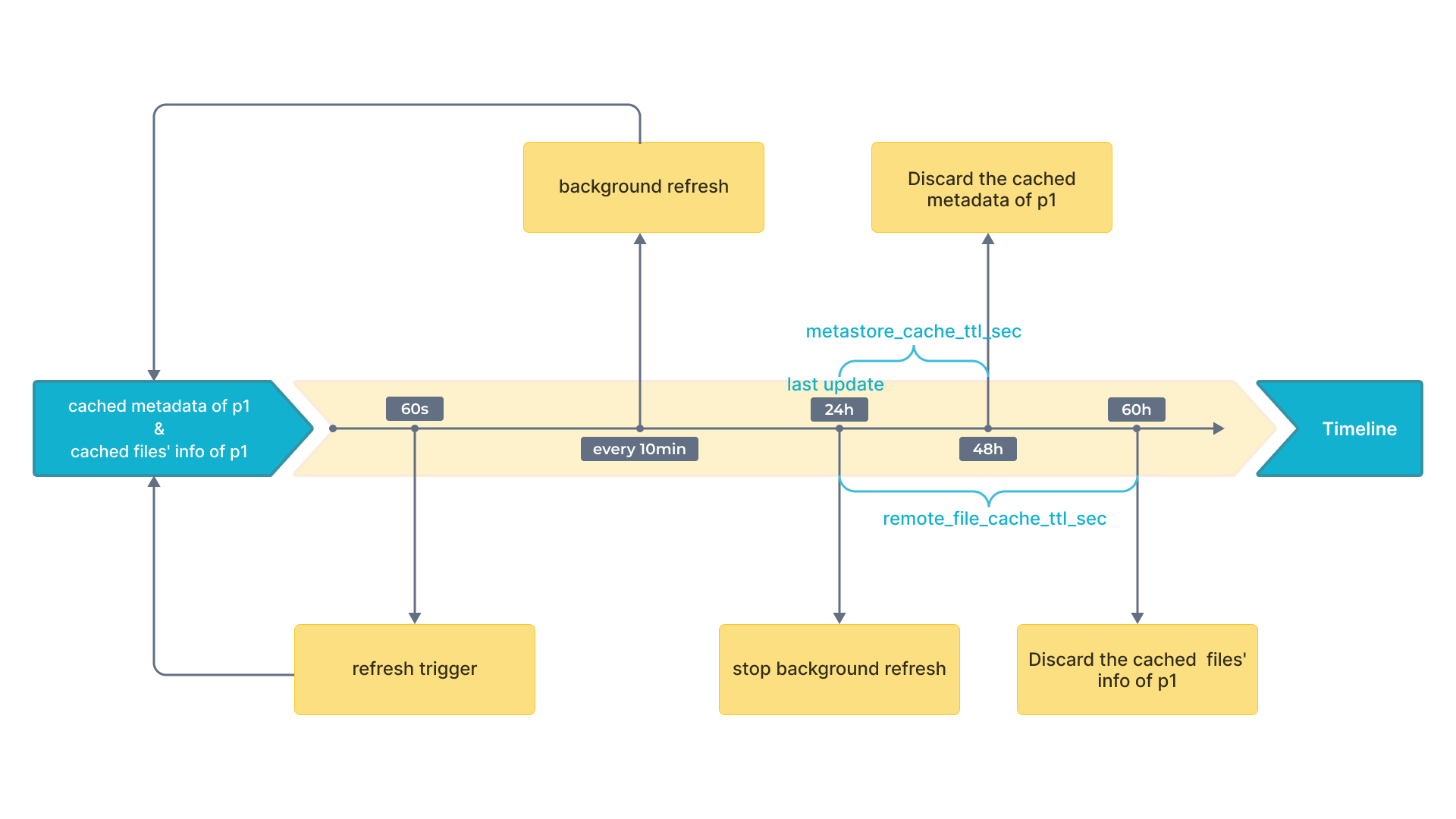
その後、StarRocks は次のルールに従ってメタデータを更新または破棄します:
- 別のクエリが再び
p1にヒットし、最後の更新からの現在の時間が 60 秒未満の場合、StarRocks はp1のキャッシュされたメタデータまたはp1の基礎データファイルのキャッシュされたメタデータを更新しません。 - 別のクエリが再び
p1にヒットし、最後の更新からの現在時間が 60 秒を超える場合、StarRocks はp1のキャッシュされたメタデータまたはp1の基礎データファイルのキャッシュされたメタデータを更新します。 - テーブルに 24 時間以内にアクセスがあった場合、関連するキャッシュはバックグラウンドで 10 分ごとに更新されます。
p1が最後の更新から 24 時間以内にアクセスされていない場合、StarRocks はp1のキャッシュされたメタデータを破棄します。次のクエリでメタデータがキャッシュされます。p1が最後の更新から 36 時間以内にアクセスされていない場合、StarRocks はp1の基礎データファイルのキャッシュされたメタデータを破棄します。次のクエリでメタデータがキャッシュされます。
