データレイクハウス
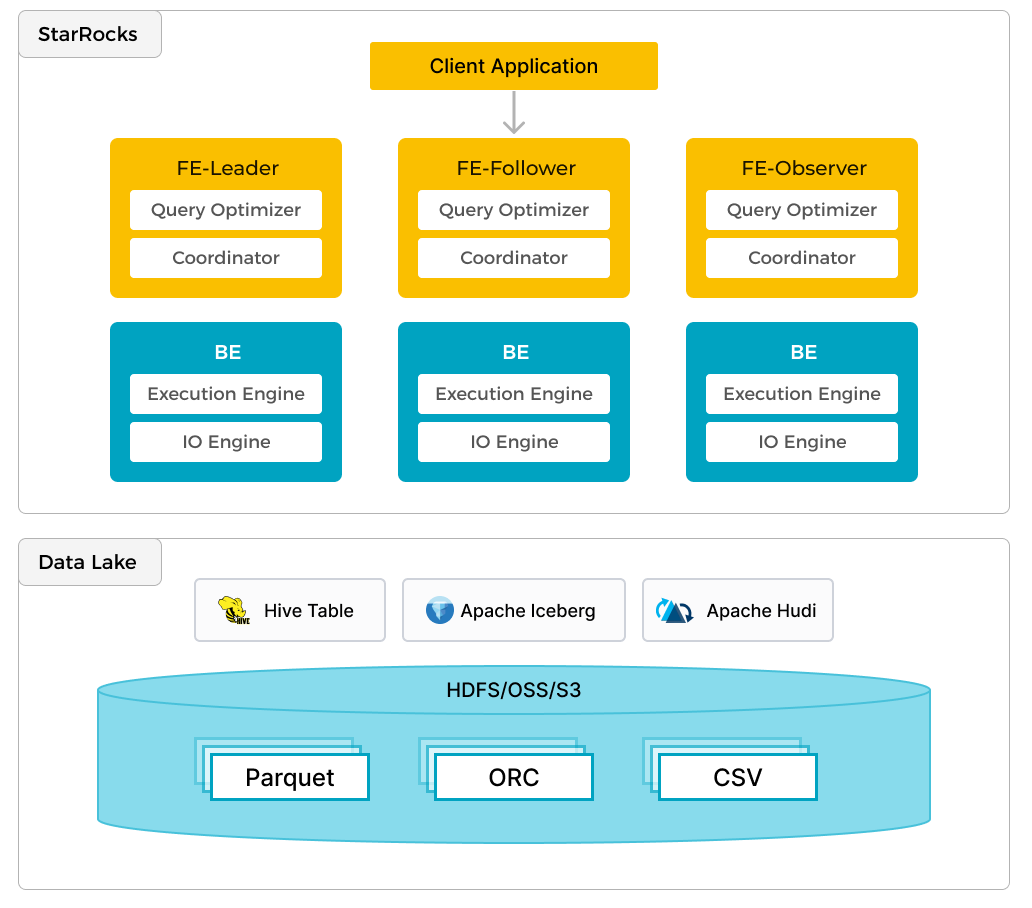
StarRocks は、ローカルデータの効率的な分析に加えて、データレイクに保存されたデータを分析するためのコンピュートエンジンとしても機能します。Apache Hudi、Apache Iceberg、Delta Lake などが含まれます。StarRocks の主要な機能の一つは、外部で管理されているメタストアへのリンクとして機能する external catalog です。この機能により、データ移行の必要なく、外部データソースをシームレスにクエリすることができます。そのため、ユーザーは HDFS や Amazon S3 などの異なるシステムから、Parquet、ORC、CSV などのさまざまなファイル形式でデータを分析できます。
前述の図は、StarRocks がデータの計算と分析を担当し、データレイクがデータの保存、組織化、メンテナンスを担当するデータレイク分析のシナリオを示しています。データレイクは、ユーザーがオープンストレージ形式でデータを保存し、柔軟なスキーマを使用し��て、さまざまな BI、AI、アドホック、およびレポート用途の「単一の真実の源」に基づくレポートを作成することを可能にします。StarRocks は、そのベクトル化エンジンと CBO の利点を十分に活用し、データレイク分析のパフォーマンスを大幅に向上させます。
主要な考え方
- オープンデータフォーマット: JSON、Parquet、Avro など、さまざまなデータタイプをサポートし、構造化データと非構造化データの両方の保存と処理を容易にします。
- メタデータ管理: Iceberg テーブルフォーマットのような形式を利用して、データを効率的に整理し管理する共有メタデータレイヤーを実装します。
- ガバナンスとセキュリティ: データのセキュリティ、プライバシー、コンプライアンスのための強力な組み込みメカニズムを備え、データの整合性と信頼性を確保します。
データレイクハウスアーキテクチャの利点
- 柔軟性とスケーラビリティ: 多様なデータタイプをシームレスに管理し、組織のニーズに応じてスケールします。
- コスト効率: 従来の方法と比較して、データの保存と処理のための経済的な代替手段を提供します。
- データガバナンスの強化: データの制御、管理、整合性を向上させ、信頼性のある安全なデータ処理を保証します。
- AI と分析の準備: 機械学習や AI 駆動のデータ処理を含む複雑な分析タスクに最適です。
StarRocks のアプローチ
考慮すべき重要な点は次のとおりです:
- catalog またはメタデータサービスとの統合の標準化
- コンピュートノードの弾力的なスケーラビリティ
- 柔軟なキャッシングメカニズム
Catalogs
StarRocks には内部と外部の 2 種類の catalog があります。内部 catalog には StarRocks データベース内に保存されたデータのメタデータが含まれています。外部 catalog は、Hive、Iceberg、Delta Lake、Hudi によって管理されるデータを含む、外部に保存されたデータを扱うために使用されます。他にも多くの外部システムがあり、リンクはページ下部の「More Information」セクションにあります。
コンピュートノード (CN) のスケーリング
ストレージとコンピュートの分離により、スケーリングの複雑さが軽減されます。StarRocks のコンピュートノードはローカルキャッシュのみを保存しているため、ロードに応じてノードを追加または削除できます。
データキャッシュ
コンピュートノード上のキャッシュはオプションです。コンピュートノードが急速に変化するロードパターンに基づいてすばやく起動および停止する場合や、クエリが最新のデータに対してのみ行われる場合、データをキャッシュする意味がないかもしれません。
詳細は Catalog docs にあります。
