データロードに関する概念
このトピックでは、データロードに関する一般的な概念と情報を紹介します。
Privileges
StarRocks のテーブルにデータを ロード するには、その StarRocks テーブルに対して INSERT 権限を持つユーザーである必要があります。INSERT 権限がない場合は、GRANT に記載されている手順に従って、StarRocks クラスターに接続するために使用するユーザーに INSERT 権限を付与してください。構文は GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>} です。
ラベリング
StarRocks にデータをロードするには、ロードジョブを実行します。各ロードジョブには、ユーザーが指定するか StarRocks が自動生成する一意のラベルがあり、ジョブを識別します。各ラベルは 1 つのロードジョブにのみ使用できます。ロードジョブが完了すると、そのラベルは他のロードジョブには再利用できません。失敗したロードジョブのラベルのみ再利用可能です。
Atomicity
StarRocks が提供するすべてのロード方法はアトミシティを保証します。アトミシティとは、ロードジョブ内の適格なデータがすべて正常にロ�ードされるか、まったくロードされないことを意味します。適格なデータの一部がロードされ、他のデータがロードされないということはありません。適格なデータには、データ型変換エラーなどの品質問題によりフィルタリングされたデータは含まれないことに注意してください。
Protocols
StarRocks は、ロードジョブを送信するために使用できる 2 つの通信プロトコルをサポートしています: MySQL と HTTP。StarRocks がサポートするすべてのロード方法のうち、HTTP を使用するのは Stream Load のみであり、他はすべて MySQL を使用します。
Data types
StarRocks はすべてのデータ型のデータロードをサポートしています。特定のデータ型のロードに関する制限に注意する必要があります。詳細については、Data types を参照してください。
Strict mode
Strict mode は、データロードのために設定できるオプションのプロパティです。ロードの動作と最終的なロードデータに影響を与えます。詳細は Strict mode を参照してください。
Loading modes
StarRocks は 2 つのロードモードをサポートしています: 同期ロードモードと非同期ロードモード。
外部プログラムを使用してデータをロードする場合、ビジネス要件に最も適したロードモードを選択してから、選択したロード方法を決定する必要があります。
Synchronous loading
同期ロードモードでは、ロードジョブを送信した後、StarRocks はジョブを同期的に実行してデータをロードし、ジョブが終了した後にジョブの結果を返します。ジョブの結果に基づいてジョブが成功したかどうかを確認できます。
StarRocks は、同期ロードをサポートする 2 つの�ロード方法を提供しています: Stream Load と INSERT。
同期ロードのプロセスは次のとおりです。
-
ロードジョブを作成します。
-
StarRocks によって返されたジョブ結果を確認します。
-
ジョブ結果に基づいてジョブが成功したかどうかを確認します。ジョブ結果がロード失敗を示している場合は、ジョブを再試行できます。
Asynchronous loading
非同期ロードモードでは、ロードジョブを送信した後、StarRocks はすぐにジョブ作成結果を返します。
-
結果がジョブ作成の成功を示している場合、StarRocks はジョブを非同期で実行します。ただし、それはデータが正常にロードされたことを意味するわけではありません。ステートメントまたはコマンドを使用してジョブのステータスを確認する必要があります。その後、ジョブステータスに基づいてデータが正常にロードされたかどうかを判断できます。
-
結果がジョブ作成の失敗を示している場合、失敗情報に基づいてジョブを再試行する必要があるかどうかを判断できます。
テーブルに対して異なる書き込みクォーラムを設定できます。つまり、StarRocks がロードタスクを成功と判断する前に、ロード成功を返す必要があるレプリカの数を指定できます。write_quorum プロパティを追加して CREATE TABLE するときに書き込みクォーラムを指定するか、ALTER TABLE を使用して既存のテーブルにこのプロパティを追加できます。
StarRocks は、非同期ロードをサポートする 4 つのロード方法を提供しています: Broker Load、Pipe、Routine Load、および Spark Load。
非同期ロードのプロセスは次のとおりです。
-
ロードジョブを作成します。
-
StarRocks によって返されたジョブ作成結果を確認し、ジョブが正常に作成されたかどうかを判断します。
-
ジョブ作成が成功�した場合、ステップ 3 に進みます。
-
ジョブ作成が失敗した場合、ステップ 1 に戻ります。
-
-
ステートメントまたはコマンドを使用してジョブのステータスを確認し、ジョブステータスが FINISHED または CANCELLED になるまで確認します。
Workflow of Broker Load or Spark Load
Broker Load または Spark Load ジョブのワークフローは、次の図に示す 5 つのステージで構成されています。
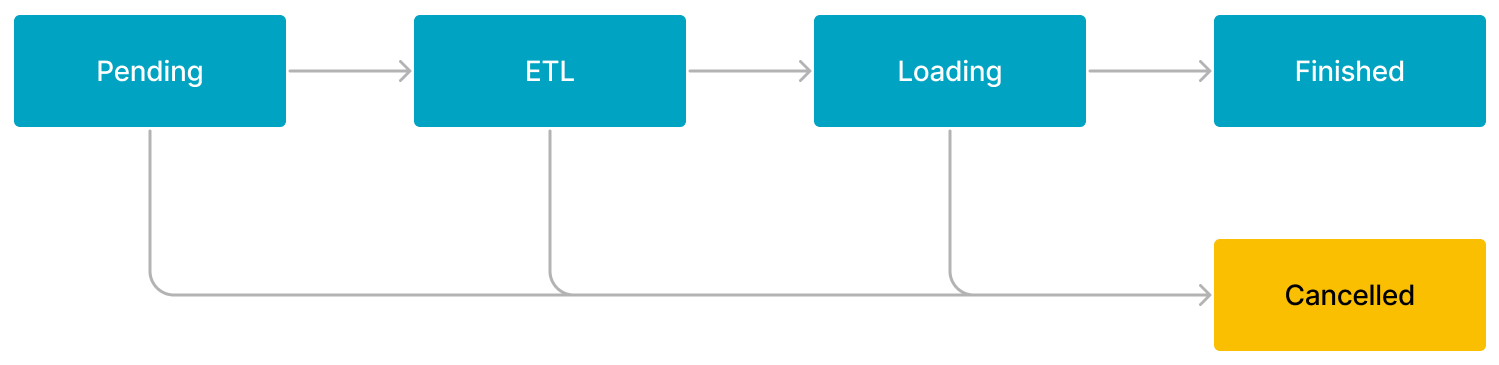
ワークフローは次のように説明されます。
-
PENDING
ジョブは FE によってスケジュールされるのを待っているキューにあります。
-
ETL
FE はデータを前処理し、クレンジング、パーティショニング、ソート、および集約を行います。
ETL ステージは Spark Load ジョブのみにあります。Broker Load ジョブはこのステージをスキップします。
-
LOADING
FE はデータをクレンジングおよび変換し、その後データを BEs または CNs に送信します。すべてのデータがロードされると、データは効果を発揮するのを待っているキューに入ります。この時点で、ジョブのステータスは LOADING のままです。
-
FINISHED
ロードが完了し、関与するすべてのデータが効果を発揮すると、ジョブのステータスは FINISHED になります。この時点で、データをクエリできます。FINISHED は最終的なジョブ状態です。
-
CANCELLED
ジョブのステータスが FINISHED になる前に、いつでもジョブをキャンセルできます。さらに、StarRocks はロードエラーが発生した場合にジョブを自動的にキャンセルできます。ジョブがキャンセルされると、ジョブのステータスは CANCELLED になり、キャンセル前に行われたすべてのデータ更新が元に戻されます。CANCELLED も最終的なジョブ状態です。
Workflow of Pipe
Pipe ジョブのワークフローは次のように説明されます。
-
ジョブは MySQL クライアントから FE に送信されます。
-
FE は、指定されたパスに保存されているデータファイルをその数またはサイズに基づいて分割し、ジョブを小さな連続タスクに分解します。タスクは作成後、スケジュールを待っているキューに入ります。
-
FE はキューからタスクを取得し、INSERT INTO SELECT FROM FILES ステートメントを呼び出して各タスクを実行します。
-
データロードが完了します:
-
ジョブ作成時に
"AUTO_INGEST" = "FALSE"が指定されている場合、指定されたパスに保存されているすべてのデータファイルのデータがロードされた後にジョブが完了します。 -
ジョブ作成時に
"AUTO_INGEST" = "TRUE"が指定されている場合、FE はデータファイルの変更を監視し続け、データファイルから新しいまたは更新されたデータを自動的に宛先の StarRocks テーブルにロードします。
-
Workflow of Routine Load
Routine Load ジョブのワークフローは次のように説明されます。
-
ジョブは MySQL クライアントから FE に送信されます。
-
FE はジョブを複数のタスクに分割します。各タスクは、複数のパーティションからデータをロードするように設計されています。
-
FE はタスクを指定された BEs または CNs に配布します。
-
BEs または CNs はタスクを実行し、タスクが完了した後に FE に報告します。
-
FE は、BEs からの報告に基づいて、後続のタスクを生成し、失敗したタスクがあれば再試行し、またはタスクスケジューリングを一時停止します。
